Microgpt
This is a brief guide to my new art project microgpt, a single file of 200 lines of pure Python with no dependencies that trains and inferences a GPT. This file contains the full algorithmic content of what is needed: dataset of documents, tokenizer, autograd engine, a GPT-2-like neural network architecture, the Adam optimizer, training loop, and inference loop. Everything else is just efficiency. I cannot simplify this any further. This script is the culmination of multiple projects (micrograd, makemore, nanogpt, etc.) and a decade-long obsession to simplify LLMs to their bare essentials, and I think it is beautiful 🥹. It even breaks perfectly across 3 columns: 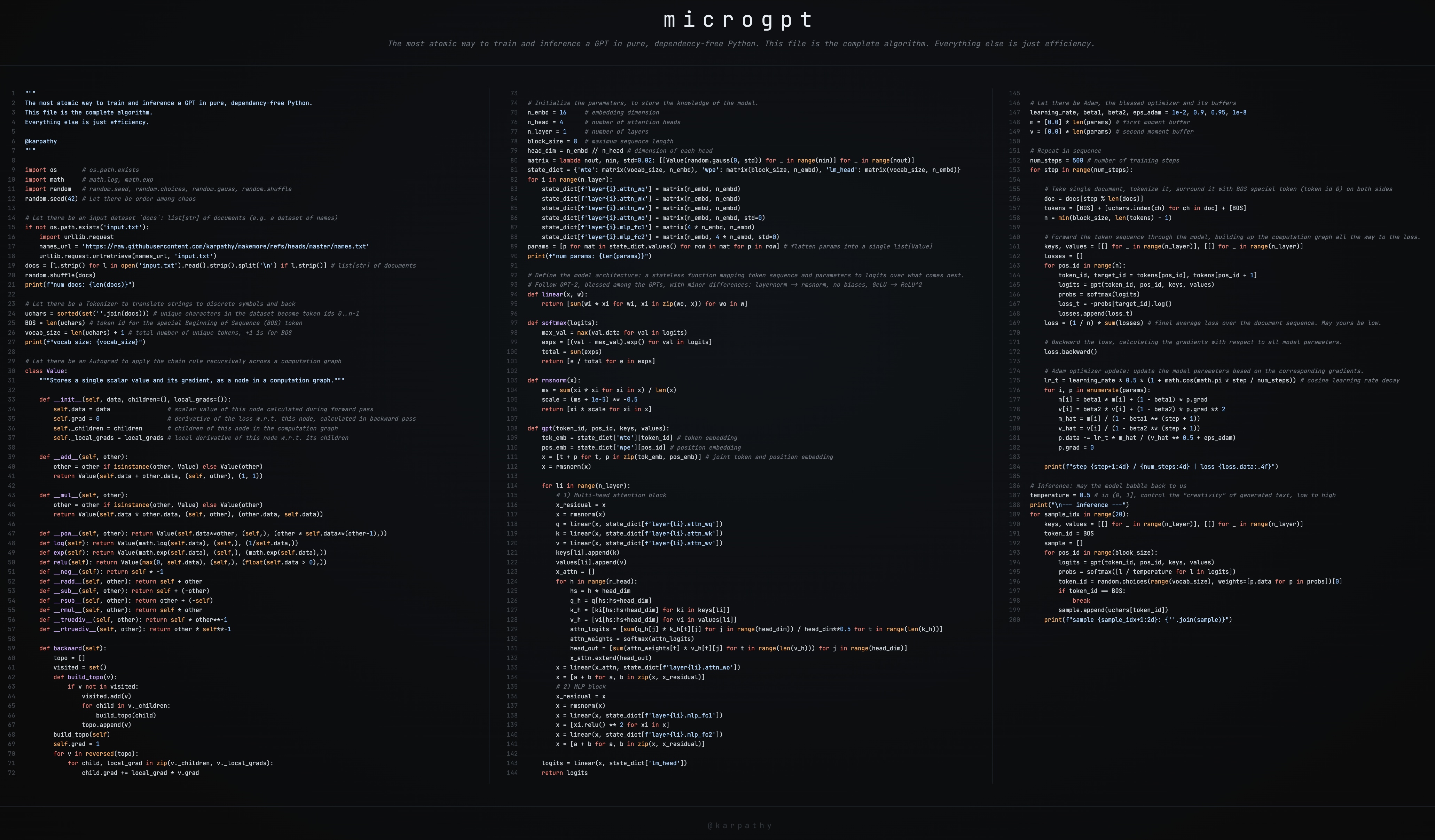 Where to find it: This GitHub gist has the full source code: microgpt.py It’s also available on this web page: https://karpathy.ai/microgpt.html * Also available as a Google Colab notebook The following is my guide on stepping an interested reader through the code. Dataset ------- The fuel of large language models is a stream of text data, optionally separated into a set of documents. In production-grade applications, each document would be an internet web page but for microgpt we use a simpler example of 32,000 names, one per line: # Let there be an input dataset
Where to find it: This GitHub gist has the full source code: microgpt.py It’s also available on this web page: https://karpathy.ai/microgpt.html * Also available as a Google Colab notebook The following is my guide on stepping an interested reader through the code. Dataset ------- The fuel of large language models is a stream of text data, optionally separated into a set of documents. In production-grade applications, each document would be an internet web page but for microgpt we use a simpler example of 32,000 names, one per line: # Let there be an input dataset docs: list[str] of documents (e.g. a dataset of names) if not os.path.exists('input.txt'): import urllib.request names_url = 'https://raw.githubusercontent.com/karpathy/makemore/refs/heads/master/names.txt' urllib.request.urlretrieve(names_url, 'input.txt') docs = [l.strip() for l in open('input.txt').read().strip().split('\n') if l.strip()] # list[str] of documents random.shuffle(docs) print(f"num docs: {len(docs)}") The dataset looks like this. Each name is a document: olivia isabella sophia charlotte amelia harper ... (~32,000 names follow) The goal of the model is to learn the patterns in the data and then generate similar new documents that share the statistical patterns within. As a preview, by the end of the script our model will generate (“hallucinate”!) new, plausible-sounding names. Skipping ahead, we’ll get: sample 1: kamon sample 2: ann sample 3: karai sample 4: jaire sample 5: vialan sample 6: karia sample 7: yeran sample 8: anna sample 9: areli sample 10: kaina sample 11: konna sample 12: keylen sample 13: liole sample 14: alerin sample 15: earan sample 16: lenne sample 17: kana sample 18: lara sample 19: alela sample 20: anton It doesn’t look like much, but from the perspective of a model like ChatGPT, your conversation with it is just a funny looking “document”. When you initialize the document with your prompt, the model’s response from its perspective is just a statistical document completion. Tokenizer --------- Under the hood, neural networks work with numbers, not characters, so we need a way to convert text into a sequence of integer token ids and back. Production tokenizers like tiktoken (used by GPT-4) operate on chunks of characters for efficiency, but the simplest possible tokenizer just assigns one integer to each unique character in the dataset: # Let there be a Tokenizer to translate strings to discrete symbols and back uchars = sorted(set(''.join(docs))) # unique characters in the dataset become token ids 0..n-1 BOS = len(uchars) # token id for the special Beginning of Sequence (BOS) token vocab_size = len(uchars) + 1 # total number of unique tokens, +1 is for BOS print(f"vocab size: {vocab_size}") In the code above, we collect all unique characters across the dataset (which are just all the lowercase letters a-z), sort them, and each letter gets an id by its index. Note that the integer values themselves have no meaning at all; each token is just a separate discrete symbol. Instead of 0, 1, 2 they might as well be different emoji. In addition, we create one more special token called BOS (Beginning of Sequence), which acts as a delimiter: it tells the model “a new document starts/ends here”. Later during training, each document gets wrapped with BOS on both sides: [BOS, e, m, m, a, BOS]. The model learns that BOS initates a new name, and that another BOS ends it. Therefore, we have a final vocavulary of 27 (26 possible lowercase characters a-z and +1 for the BOS token). Autograd -------- Training a neural network requires gradients: for each parameter in the model, we need to know “if I nudge this number up a little, does the loss go up or down, and by how much?”. The computation graph has many inputs (the model parameters and the input tokens) but funnels down to a single scalar output: the loss (we’ll define exactly what the loss is below). Backpropagation starts at that single output and works backwards through the graph, computing the gradient of the loss with respect to every input. It relies on the chain rule from calculus. In production, libraries like PyTorch handle this automatically. Here, we implement it from scratch in a single class called Value: class Value: __slots__ = ('data', 'grad', '_children', '_local_grads') def __init__(self, data, children=(), local_grads=()): self.data = data # scalar value of this node calculated during forward pass self.grad = 0 # derivative of the loss w.r.t. this node, calculated in backward pass self._children = children # children of this node in the computation graph self._local_grads = local_grads # local derivative of this node w.r.t. its children def __add__(self, other): other = other if isinstance(other, Value) else Value(other) return Value(self.data + other.data, (self, other), (1, 1)) def __mul__(self, other): other = other if isinstance(other, Value) else Value(other) return Value(self.data other.data, (self, other), (other.data, self.data)) def __pow__(self, other): return Value(self.dataother, (self,), (other self.data*(other-1),)) def log(self): return Value(math.log(self.data), (self,), (1/self.data,)) def exp(self): return Value(math.exp(self.data), (self,), (math.exp(self.data),)) def relu(self): return Value(max(0, self.data), (self,), (float(self.data > 0),)) def __neg__(self): return self -1 def __radd__(self, other): return self + other def __sub__(self, other): return self + (-other) def __rsub__(self, other): return other + (-self) def __rmul__(self, other): return self other def __truediv__(self, other): return self other*-1 def __rtruediv__(self, other): return other self*-1 def backward(self): topo = [] visited = set() def build_topo(v): if v not in visited: visited.add(v) for child in v._children: build_topo(child) topo.append(v) build_topo(self) self.grad = 1 for v in reversed(topo): for child, local_grad in zip(v._children, v._local_grads): child.grad += local_grad v.grad I realize that this is the most mathematically and algorithmically intense part and I have a 2.5 hour video on it: micrograd video. Briefly, a Value wraps a single scalar number (.data) and tracks how it was computed. Think of each operation as a little lego block: it takes some inputs, produces an output (the forward pass), and it knows how its output would change with respect to each of its inputs (the local gradient). That’s all the information autograd needs from each block. Everything else is just the chain rule, stringing the blocks together. Every time you do math with Value objects (add, multiply, etc.), the result is a new Value that remembers its inputs (_children) and the local derivative of that operation (_local_grads). For example, __mul__ records that ∂(a⋅b)∂a=b and ∂(a⋅b)∂b=a. The full set of lego blocks: | Operation | Forward | Local gradients | | --- | --- | --- | | a + b | a+b | ∂∂a=1,∂∂b=1 | | a * b | a⋅b | ∂∂a=b,∂∂b=a | | a ** n | a n | ∂∂a=n⋅a n−1 | | log(a) | ln(a) | ∂∂a=1 a | | exp(a) | e a | ∂∂a=e a | | relu(a) | max(0,a) | ∂∂a=1 a>0 | The backward() method walks this graph in reverse topological order (starting from the loss, ending at the parameters), applying the chain rule at each step. If the loss is L and a node v has a child c with local gradient ∂v∂c, then: ∂L∂c+=∂v∂c⋅∂L∂v This looks a bit scary if you’re not comfortable with your calculus, but this is literally just multiplying two numbers in an intuitive way. One way to see it looks as follows: “If a car travels twice as fast as a bicycle and the bicycle is four times as fast as a walking man, then the car travels 2 x 4 = 8 times as fast as the man.” The chain rule is the same idea: you multiply the rates of change along the path. We kick things off by setting self.grad = 1 at the loss node, because ∂L∂L=1: the loss’s rate of change with respect to itself is trivially 1. From there, the chain rule just multiplies local gradients along every path back to the parameters. Note the += (accumulation, not assignment). When a value is used in multiple places in the graph (i.e. the graph branches), gradients flow back along each branch independently and must be summed. This is a consequence of the multivariable chain rule: if c contributes to L through multiple paths, the total derivative is the sum of contributions from each path. After backward() completes, every Value in the graph has a .grad containing ∂L∂v, which tells us how the final loss would change if we nudged that value. Here’s a concrete example. Note that a is used twice (the graph branches), so its gradient is the sum of both paths: a = Value(2.0) b = Value(3.0) c = a * b # c = 6.0 L = c + a # L = 8.0 L.backward() print(a.grad) # 4.0 (dL/da = b + 1 = 3 + 1, via both paths) print(b.grad) # 2.0 (dL/db = a = 2) This is exactly what PyTorch’s .backward() gives you: import torch a = torch.tensor(2.0, requires_grad=True) b = torch.tensor(3.0, requires_grad=True) c = a * b L = c + a L.backward() print(a.grad) # tensor(4.) print(b.grad) # tensor(2.) This is the same algorithm that PyTorch’s loss.backward() runs, just on scalars instead of tensors (arrays of scalars) - algorithmically identical, significantly smaller and simpler, but of course a lot less efficient. Let’s spell what the .backward() gives us above. Autograd calculated that if L = a*b + a, and a=2 and b=3, then a.grad = 4.0 is telling us about the local influence of a on L. If you wiggle the inmput a, in what direction is L changing? Here, the derivative of L w.r.t. a is 4.0, meaning that if we increase a by a tiny amount (say 0.001), L would increase by about 4x that (0.004). Similarly, b.grad = 2.0 means the same nudge to b would increase L by about 2x that (0.002). In other words, these gradients tell us the direction (positive or negative depending on the sign), and the steepness (the magnitude) of the influence of each individual input on the final output (the loss). This then allows us to interately nudge the parameters of our neural network to lower the loss, and hence improve its predictions. Parameters ---------- The parameters are the knowledge of the model. They are a large collection of floating point numbers (wrapped in Value for autograd) that start out random and are iteratively optimized during training. The exact role of each parameter will make more sense once we define the model architecture below, but for now we just need to initialize them: n_embd = 16 # embedding dimension n_head = 4 # number of attention heads n_layer = 1 # number of layers block_size = 16 # maximum sequence length head_dim = n_embd // n_head # dimension of each head matrix = lambda nout, nin, std=0.08: [[Value(random.gauss(0, std)) for _ in range(nin)] for _ in range(nout)] state_dict = {'wte': matrix(vocab_size, n_embd), 'wpe': matrix(block_size, n_embd), 'lm_head': matrix(vocab_size, n_embd)} for i in range(n_layer): state_dict[f'layer{i}.attn_wq'] = matrix(n_embd, n_embd) state_dict[f'layer{i}.attn_wk'] = matrix(n_embd, n_embd) state_dict[f'layer{i}.attn_wv'] = matrix(n_embd, n_embd) state_dict[f'layer{i}.attn_wo'] = matrix(n_embd, n_embd) state_dict[f'layer{i}.mlp_fc1'] = matrix(4 n_embd, n_embd) state_dict[f'layer{i}.mlp_fc2'] = matrix(n_embd, 4 n_embd) params = [p for mat in state_dict.values() for row in mat for p in row] print(f"num params: {len(params)}") Each parameter is initialized to a small random number drawn from a Gaussian distribution. The state_dict organizes them into named matrices (borrowing PyTorch’s terminology): embedding tables, attention weights, MLP weights, and a final output projection. We also flatten all parameters into a single list params so the optimizer can loop over them later. In our tiny model this comes out to 4,192 parameters. GPT-2 had 1.6 billion, and modern LLMs have hundreds of billions. Architecture ------------ The model architecture is a stateless function: it takes a token, a position, the parameters, and the cached keys/values from previous positions, and returns logits (scores) over what token the model things should come next in the sequence. We follow GPT-2 with minor simplifications: RMSNorm instead of LayerNorm, no biases, and ReLU instead of GeLU. First, three small helper functions: def linear(x, w): return [sum(wi * xi for wi, xi in zip(wo, x)) for wo in w] linear is a matrix-vector multiply. It takes a vector x and a weight matrix w, and computes one dot product per row of w. This is the fundamental building block of neural networks: a learned linear transformation. def softmax(logits): max_val = max(val.data for val in logits) exps = [(val - max_val).exp() for val in logits] total = sum(exps) return [e / total for e in exps] softmax converts a vector of raw scores (logits), which can range from −∞ to +∞, into a probability distribution: all values end up in [0,1] and sum to 1. We subtract the max first for numerical stability (it doesn’t change the result mathematically, but prevents overflow in exp). def rmsnorm(x): ms = sum(xi xi for xi in x) / len(x) scale = (ms + 1e-5) -0.5 return [xi scale for xi in x] rmsnorm (Root Mean Square Normalization) rescales a vector so its values have unit root-mean-square. This keeps activations from growing or shrinking as they flow through the network, which stabilizes training. It’s a simpler variant of the LayerNorm used in the original GPT-2. Now the model itself: def gpt(token_id, pos_id, keys, values): tok_emb = state_dict['wte'][token_id] # token embedding pos_emb = state_dict['wpe'][pos_id] # position embedding x = [t + p for t, p in zip(tok_emb, pos_emb)] # joint token and position embedding x = rmsnorm(x) for li in range(n_layer): # 1) Multi-head attention block x_residual = x x = rmsnorm(x) q = linear(x, state_dict[f'layer{li}.attn_wq']) k = linear(x, state_dict[f'layer{li}.attn_wk']) v = linear(x, state_dict[f'layer{li}.attn_wv']) keys[li].append(k) values[li].append(v) x_attn = [] for h in range(n_head): hs = h head_dim q_h = q[hs:hs+head_dim] k_h = [ki[hs:hs+head_dim] for ki in keys[li]] v_h = [vi[hs:hs+head_dim] for vi in values[li]] attn_logits = [sum(q_h[j] k_h[t][j] for j in range(head_dim)) / head_dim*0.5 for t in range(len(k_h))] attn_weights = softmax(attn_logits) head_out = [sum(attn_weights[t] v_h[t][j] for t in range(len(v_h))) for j in range(head_dim)] x_attn.extend(head_out) x = linear(x_attn, state_dict[f'layer{li}.attn_wo']) x = [a + b for a, b in zip(x, x_residual)] # 2) MLP block x_residual = x x = rmsnorm(x) x = linear(x, state_dict[f'layer{li}.mlp_fc1']) x = [xi.relu() for xi in x] x = linear(x, state_dict[f'layer{li}.mlp_fc2']) x = [a + b for a, b in zip(x, x_residual)] logits = linear(x, state_dict['lm_head']) return logits The function processes one token (of id token_id) at a specific position in time (pos_id), and some context from the previous iterations summarized by the activations in keys and values, known as the KV Cache. Here’s what happens step by step: Embeddings. The neural network can’t process a raw token id like 5 directly. It can only work with vectors (lists of numbers). So we associate a learned vector with each possible token, and feed that in as its neural signature. The token id and position id each look up a row from their respective embedding tables (wte and wpe). These two vectors are added together, giving the model a representation that encodes both _what_ the token is and _where_ it is in the sequence. Modern LLMs usually skip the position embedding and introduce other relative-based positioning schemes, e.g. RoPE. Attention block. The current token is projected into three vectors: a query (Q), a key (K), and a value (V). Intuitively, the query says “what am I looking for?”, the key says “what do I contain?”, and the value says “what do I offer if selected?”. For example, in the name “emma”, when the model is at the second “m” and trying to predict what comes next, it might learn a query like “what vowels appeared recently?” The earlier “e” would have a key that matches this query well, so it gets a high attention weight, and its value (information about being a vowel) flows into the current position. The key and value are appended to the KV cache so previous positions are available. Each attention head computes dot products between its query and all cached keys (scaled by d h e a d), applies softmax to get attention weights, and takes a weighted sum of the cached values. The outputs of all heads are concatenated and projected through attn_wo. It’s worth emphasizing that the Attention block is the exact and only place where a token at position t gets to “look” at tokens in the past 0..t-1. Attention is a token communication mechanism. MLP block. MLP is short for “multilayer perceptron”, it is a two-layer feed-forward network: project up to 4x the embedding dimension, apply ReLU, project back down. This is where the model does most of its “thinking” per position. Unlike attention, this computation is fully local to time t. The Transformer intersperses communication (Attention) with computation (MLP). Residual connections. Both the attention and MLP blocks add their output back to their input (x = [a + b for ...]). This lets gradients flow directly through the network and makes deeper models trainable. Output. The final hidden state is projected to vocabulary size by lm_head, producing one logit per token in the vocabulary. In our case, that’s just 27 numbers. Higher logit = the model thinks that corresponding token is more likely to come next. You might notice that we’re using a KV cache during training, which is unusual. People typically associate the KV cache with inference only. But the KV cache is conceptually always there, even during training. In production implementations, it’s just hidden inside