We deserve a better streams API for JavaScript
2026-02-27 24 min read  Handling data in streams is fundamental to how we build applications. To make streaming work everywhere, the WHATWG Streams Standard (informally known as "Web streams") was designed to establish a common API to work across browsers and servers. It shipped in browsers, was adopted by Cloudflare Workers, Node.js, Deno, and Bun, and became the foundation for APIs like fetch(). It's a significant undertaking, and the people who designed it were solving hard problems with the constraints and tools they had at the time. But after years of building on Web streams — implementing them in both Node.js and Cloudflare Workers, debugging production issues for customers and runtimes, and helping developers work through far too many common pitfalls — I've come to believe that the standard API has fundamental usability and performance issues that cannot be fixed easily with incremental improvements alone. The problems aren't bugs; they're consequences of design decisions that may have made sense a decade ago, but don't align with how JavaScript developers write code today. This post explores some of the fundamental issues I see with Web streams and presents an alternative approach built around JavaScript language primitives that demonstrate something better is possible. In benchmarks, this alternative can run anywhere between 2x to _120x_ faster than Web streams in every runtime I've tested it on (including Cloudflare Workers, Node.js, Deno, Bun, and every major browser). The improvements are not due to clever optimizations, but fundamentally different design choices that more effectively leverage modern JavaScript language features. I'm not here to disparage the work that came before — I'm here to start a conversation about what can potentially come next. Where we're coming from ----------------------- The Streams Standard was developed between 2014 and 2016 with an ambitious goal to provide "APIs for creating, composing, and consuming streams of data that map efficiently to low-level I/O primitives." Before Web streams, the web platform had no standard way to work with streaming data. Node.js already had its own streaming API at the time that was ported to also work in browsers, but WHATWG chose not to use it as a starting point given that it is chartered to only consider the needs of Web browsers. Server-side runtimes only adopted Web streams later, after Cloudflare Workers and Deno each emerged with first-class Web streams support and cross-runtime compatibility became a priority. The design of Web streams predates async iteration in JavaScript. The [
Handling data in streams is fundamental to how we build applications. To make streaming work everywhere, the WHATWG Streams Standard (informally known as "Web streams") was designed to establish a common API to work across browsers and servers. It shipped in browsers, was adopted by Cloudflare Workers, Node.js, Deno, and Bun, and became the foundation for APIs like fetch(). It's a significant undertaking, and the people who designed it were solving hard problems with the constraints and tools they had at the time. But after years of building on Web streams — implementing them in both Node.js and Cloudflare Workers, debugging production issues for customers and runtimes, and helping developers work through far too many common pitfalls — I've come to believe that the standard API has fundamental usability and performance issues that cannot be fixed easily with incremental improvements alone. The problems aren't bugs; they're consequences of design decisions that may have made sense a decade ago, but don't align with how JavaScript developers write code today. This post explores some of the fundamental issues I see with Web streams and presents an alternative approach built around JavaScript language primitives that demonstrate something better is possible. In benchmarks, this alternative can run anywhere between 2x to _120x_ faster than Web streams in every runtime I've tested it on (including Cloudflare Workers, Node.js, Deno, Bun, and every major browser). The improvements are not due to clever optimizations, but fundamentally different design choices that more effectively leverage modern JavaScript language features. I'm not here to disparage the work that came before — I'm here to start a conversation about what can potentially come next. Where we're coming from ----------------------- The Streams Standard was developed between 2014 and 2016 with an ambitious goal to provide "APIs for creating, composing, and consuming streams of data that map efficiently to low-level I/O primitives." Before Web streams, the web platform had no standard way to work with streaming data. Node.js already had its own streaming API at the time that was ported to also work in browsers, but WHATWG chose not to use it as a starting point given that it is chartered to only consider the needs of Web browsers. Server-side runtimes only adopted Web streams later, after Cloudflare Workers and Deno each emerged with first-class Web streams support and cross-runtime compatibility became a priority. The design of Web streams predates async iteration in JavaScript. The [for await...of](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Statements/for-await...of) syntax didn't land until ES2018, two years after the Streams Standard was initially finalized. This timing meant the API couldn't initially leverage what would eventually become the idiomatic way to consume asynchronous sequences in JavaScript. Instead, the spec introduced its own reader/writer acquisition model — and that decision rippled through every aspect of the API. 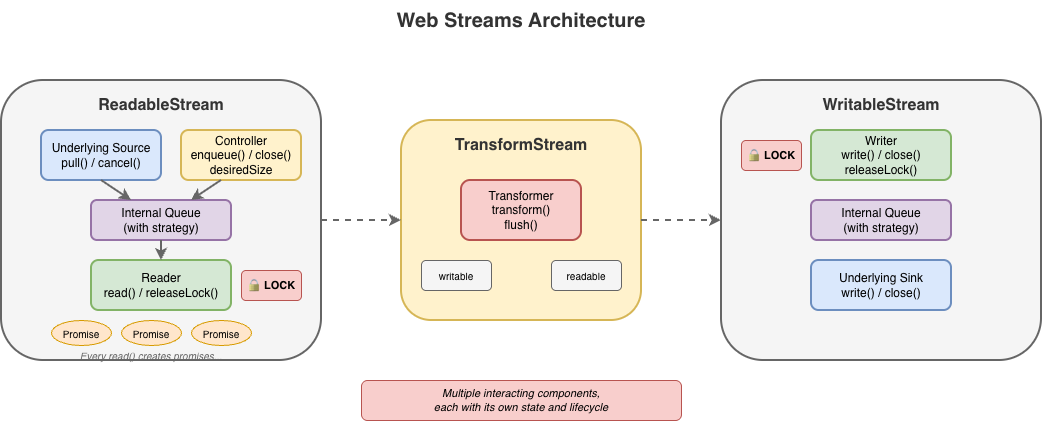 #### Excessive ceremony for common operations The most common task with streams is reading them to completion. Here's what that looks like with Web streams: // First, we acquire a reader that gives an exclusive lock // on the stream... const reader = stream.getReader(); const chunks = []; try { // Second, we repeatedly call read and await on the returned // promise to either yield a chunk of data or indicate we're // done. while (true) { const { value, done } = await reader.read(); if (done) break; chunks.push(value); } finally { // Finally, we release the lock on the stream reader.releaseLock(); You might assume this pattern is inherent to streaming. It isn't. The reader acquisition, the lock management, and the
#### Excessive ceremony for common operations The most common task with streams is reading them to completion. Here's what that looks like with Web streams: // First, we acquire a reader that gives an exclusive lock // on the stream... const reader = stream.getReader(); const chunks = []; try { // Second, we repeatedly call read and await on the returned // promise to either yield a chunk of data or indicate we're // done. while (true) { const { value, done } = await reader.read(); if (done) break; chunks.push(value); } finally { // Finally, we release the lock on the stream reader.releaseLock(); You might assume this pattern is inherent to streaming. It isn't. The reader acquisition, the lock management, and the { value, done } protocol are all just design choices, not requirements. They are artifacts of how and when the Web streams spec was written. Async iteration exists precisely to handle sequences that arrive over time, but async iteration did not yet exist when the streams specification was written. The complexity here is pure API overhead, not fundamental necessity. Consider the alternative approach now that Web streams now do support for await...of: const chunks = []; for await (const chunk of stream) { chunks.push(chunk); This is better in that there is far less boilerplate, but it doesn't solve everything. Async iteration was retrofitted onto an API that wasn't designed for it, and it shows. Features like BYOB (bring your own buffer) reads aren't accessible through iteration. The underlying complexity of readers, locks, and controllers are still there, just hidden. When something does go wrong, or when additional features of the API are needed, developers find themselves back in the weeds of the original API, trying to understand why their stream is "locked" or why releaseLock() didn't do what they expected or hunting down bottlenecks in code they don't control. #### The locking problem Web streams use a locking model to prevent multiple consumers from interleaving reads. When you call [getReader()](https://developer.mozilla.org/en-US/docs/Web/API/ReadableStream/getReader), the stream becomes locked. While locked, nothing else can read from the stream directly, pipe it, or even cancel it — only the code that is actually holding the reader can. This sounds reasonable until you see how easily it goes wrong: async function peekFirstChunk(stream) { const reader = stream.getReader(); const { value } = await reader.read(); // Oops — forgot to call reader.releaseLock() // And the reader is no longer available when we return return value; const first = await peekFirstChunk(stream); // TypeError: Cannot obtain lock — stream is permanently locked for await (const chunk of stream) { / never runs / } Forgetting [releaseLock()](https://developer.mozilla.org/en-US/docs/Web/API/ReadableStreamDefaultReader/releaseLock) permanently breaks the stream. The [locked](https://developer.mozilla.org/en-US/docs/Web/API/ReadableStream/locked)`property tells you that a stream is locked, but not why, by whom, or whether the lock is even still usable. [Piping](https://developer.mozilla.org/en-US/docs/Web/API/ReadableStream/pipeTo) internally acquires locks, making streams unusable during pipe operations in ways that aren't obvious. The semantics around releasing locks with pending reads were also unclear for years. If you called read() but didn't await it, then called releaseLock(), what happened? The spec was recently clarified to cancel pending reads on lock release — but implementations varied, and code that relied on the previous unspecified behavior can break. That said, it's important to recognize that locking in itself is not bad. It does, in fact, serve an important purpose to ensure that applications properly and orderly consume or produce data. The key challenge is with the original manual implementation of it using APIs like getReader()and releaseLock(). With the arrival of automatic lock and reader management with async iterables, dealing with locks from the users point of view became a lot easier. For implementers, the locking model adds a fair amount of non-trivial internal bookkeeping. Every operation must check lock state, readers must be tracked, and the interplay between locks, cancellation, and error states creates a matrix of edge cases that must all be handled correctly. #### BYOB: complexity without payoff [BYOB (bring your own buffer)](https://developer.mozilla.org/en-US/docs/Web/API/ReadableStreamBYOBReader) reads were designed to let developers reuse memory buffers when reading from streams — an important optimization intended for high-throughput scenarios. The idea is sound: instead of allocating new buffers for each chunk, you provide your own buffer and the stream fills it. In practice, (and yes, there are always exceptions to be found) BYOB is rarely used to any measurable benefit. The API is substantially more complex than default reads, requiring a separate reader type (ReadableStreamBYOBReader) and other specialized classes (e.g. ReadableStreamBYOBRequest), careful buffer lifecycle management, and understanding of [ArrayBuffer detachment](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/ArrayBuffer#transferring_arraybuffers) semantics. When you pass a buffer to a BYOB read, the buffer becomes detached — transferred to the stream — and you get back a different view over potentially different memory. This transfer-based model is error-prone and confusing: const reader = stream.getReader({ mode: 'byob' }); const buffer = new ArrayBuffer(1024); let view = new Uint8Array(buffer); const result = await reader.read(view); // 'view' should now be detached and unusable // (it isn't always in every impl) // result.value is a NEW view, possibly over different memory view = result.value; // Must reassign BYOB also can't be used with async iteration or TransformStreams, so developers who want zero-copy reads are forced back into the manual reader loop. For implementers, BYOB adds significant complexity. The stream must track pending BYOB requests, handle partial fills, manage buffer detachment correctly, and coordinate between the BYOB reader and the underlying source. The [Web Platform Tests for readable byte streams](https://github.com/web-platform-tests/wpt/tree/master/streams/readable-byte-streams) include dedicated test files just for BYOB edge cases: detached buffers, bad views, response-after-enqueue ordering, and more. BYOB ends up being complex for both users and implementers, yet sees little adoption in practice. Most developers stick with default reads and accept the allocation overhead. Most userland implementations of custom ReadableStream instances do not typically bother with all the ceremony required to correctly implement both default and BYOB read support in a single stream – and for good reason. It's difficult to get right and most of the time consuming code is typically going to fallback on the default read path. The example below shows what a "correct" implementation would need to do. It's big, complex, and error prone, and not a level of complexity that the typical developer really wants to have to deal with: new ReadableStream({ type: 'bytes', async pull(controller: ReadableByteStreamController) { if (offset >= totalBytes) { controller.close(); return; // Check for BYOB request FIRST const byobRequest = controller.byobRequest; if (byobRequest) { // === BYOB PATH === // Consumer provided a buffer - we MUST fill it (or part of it) const view = byobRequest.view!; const bytesAvailable = totalBytes - offset; const bytesToWrite = Math.min(view.byteLength, bytesAvailable); // Create a view into the consumer's buffer and fill it // not critical but safer when bytesToWrite != view.byteLength const dest = new Uint8Array( view.buffer, view.byteOffset, bytesToWrite // Fill with sequential bytes (our "data source") // Can be any thing here that writes into the view for (let i = 0; i < bytesToWrite; i++) { dest[i] = (offset + i) & 0xFF; offset += bytesToWrite; // Signal how many bytes we wrote byobRequest.respond(bytesToWrite); } else { // === DEFAULT READER PATH === // No BYOB request - allocate and enqueue a chunk const bytesAvailable = totalBytes - offset; const chunkSize = Math.min(1024, bytesAvailable); const chunk = new Uint8Array(chunkSize); for (let i = 0; i < chunkSize; i++) { chunk[i] = (offset + i) & 0xFF; offset += chunkSize; controller.enqueue(chunk); cancel(reason) { console.log('Stream canceled:', reason); When a host runtime provides a byte-oriented ReadableStream from the runtime itself, for instance, as the bodyof a fetch Response, it is often far easier for the runtime itself to provide an optimized implementation of BYOB reads, but those still need to be capable of handling both default and BYOB reading patterns and that requirement brings with it a fair amount of complexity. #### Backpressure: good in theory, broken in practice Backpressure — the ability for a slow consumer to signal a fast producer to slow down — is a first-class concept in Web streams. In theory. In practice, the model has some serious flaws. The primary signal is [desiredSize](https://developer.mozilla.org/en-US/docs/Web/API/ReadableStreamDefaultController/desiredSize) on the controller. It can be positive (wants data), zero (at capacity), negative (over capacity), or null (closed). Producers are supposed to check this value and stop enqueueing when it's not positive. But there's nothing enforcing this: [controller.enqueue()](https://developer.mozilla.org/en-US/docs/Web/API/ReadableStreamDefaultController/enqueue) always succeeds, even when desiredSize is deeply negative. new ReadableStream({ start(controller) { // Nothing stops you from doing this while (true) { controller.enqueue(generateData()); // desiredSize: -999999 Stream implementations can and do ignore backpressure; and some spec-defined features explicitly break backpressure. [tee()](https://developer.mozilla.org/en-US/docs/Web/API/ReadableStream/tee), for instance, creates two branches from a single stream. If one branch reads faster than the other, data accumulates in an internal buffer with no limit. A fast consumer can cause unbounded memory growth while the slow consumer catches up — and there's no way to configure this or opt out beyond canceling the slower branch. Web streams do provide clear mechanisms for tuning backpressure behavior in the form of the highWaterMark option and customizable size calculations, but these are just as easy to ignore as desiredSize, and many applications simply fail to pay attention to them. The same issues exist on the WritableStream side. A WritableStream has a highWaterMark and desiredSize. There is a writer.ready promise that producers of data are supposed to pay attention but often don't. const writable = getWritableStreamSomehow(); const writer = writable.getWriter(); // Producers are supposed to wait for the writer.ready // It is a promise that, when resolves, indicates that // the writables internal backpressure is cleared and // it is ok to write more data await writer.ready; await writer.write(...); For implementers, backpressure adds complexity without providing guarantees. The machinery to track queue sizes, compute desiredSize, and invoke pull() at the right times must all be implemented correctly. However, since these signals are advisory, all that work doesn't actually prevent the problems backpressure is supposed to solve. #### The hidden cost of promises The Web streams spec requires promise creation at numerous points — often in hot paths and often invisible to users. Each read() call doesn't just return a promise; internally, the implementation creates additional promises for queue management, pull() coordination, and backpressure signaling. This overhead is mandated by the spec's reliance on promises for buffer management, completion, and backpressure signals. While some of it is implementation-specific, much of it is unavoidable if you're following the spec as written. For high-frequency streaming — video frames, network packets, real-time data — this overhead is significant. The problem compounds in pipelines. Each TransformStream adds another layer of promise machinery between source and sink. The spec doesn't define synchronous fast paths, so even when data is available immediately, the promise machinery still runs. For implementers, this promise-heavy design constrains optimization opportunities. The spec mandates specific promise resolution ordering, making it difficult to batch operations or skip unnecessary async boundaries without risking subtle compliance failures. There are many hidden internal optimizations that implementers do make but these can be complicated and difficult to get right. While I was writing this blog post, Vercel's Malte Ubl published their own [blog post](https://vercel.com/blog/we-ralph-wiggumed-webstreams-to-make-them-10x-faster) describing some research work Vercel has been doing around improving the performance of Node.js' Web streams implementation. In that post they discuss the same fundamental performance optimization problem that every implementation of Web streams face: > "Or consider pipeTo(). Each chunk passes through a full Promise chain: read, write, check backpressure, repeat. An {value, done} result object is allocated per read. Error propagation creates additional Promise branches. > None of this is wrong. These guarantees matter in the browser where streams cross security boundaries, where cancellation semantics need to be airtight, where you do not control both ends of a pipe. But on the server, when you are piping React Server Components through three transforms at 1KB chunks, the cost adds up. > We benchmarked native WebStream pipeThrough at 630 MB/s for 1KB chunks. Node.js pipeline() with the same passthrough transform: ~7,900 MB/s. That is a 12x gap, and the difference is almost entirely Promise and object allocation overhead." - Malte Ubl, [https://vercel.com/blog/we-ralph-wiggumed-webstreams-to-make-them-10x-faster](https://vercel.com/blog/we-ralph-wiggumed-webstreams-to-make-them-10x-faster) As part of their research, they have put together a set of proposed improvements for Node.js' Web streams implementation that will eliminate promises in certain code paths which can yield a significant performance boost up to 10x faster, which only goes to prove the point: promises, while useful, add significant overhead. As one of the core maintainers of Node.js, I am looking forward to helping Malte and the folks at Vercel get their proposed improvements landed! In a recent update made to Cloudflare Workers, I made similar kinds of modifications to an internal data pipeline that reduced the number of JavaScript promises created in certain application scenarios by up to 200x. The result is several orders of magnitude improvement in performance in those applications. ### Real-world failures #### Exhausting resources with unconsumed bodies When fetch() returns a response, the body is a [ReadableStream](https://developer.mozilla.org/en-US/docs/Web/API/Response/body). If you only check the status and don't consume or cancel the body, what happens? The answer varies by implementation, but a common outcome is resource leakage. async function checkEndpoint(url) { const response = await fetch(url); return response.ok; // Body is never consumed or cancelled // In a loop, this can exhaust connection pools for (const url of urls) { await checkEndpoint(url); This pattern has caused connection pool exhaustion in Node.js applications using [undici](https://nodejs.org/api/globals.html#fetch) (the fetch()implementation built into Node.js), and similar issues have appeared in other runtimes. The stream holds a reference to the underlying connection, and without explicit consumption or cancellation, the connection may linger until garbage collection — which may not happen soon enough under load. The problem is compounded by APIs that implicitly create stream branches. [Request.clone()](https://developer.mozilla.org/en-US/docs/Web/API/Request/clone) and [Response.clone()](https://developer.mozilla.org/en-US/docs/Web/API/Response/clone) perform implicit tee() operations on the body stream — a detail that's easy to miss. Code that clones a request for logging or retry logic may unknowingly create branched streams that need independent consumption, multiplying the resource management burden. Now, to be certain, these types of issues _are_ implementation bugs. The connection leak was definitely something that undici needed to fix in its own implementation, but the complexity of the specification does not make dealing with these types of issues easy. > "Cloning streams in Node.js's fetch() implementation is harder than it looks. When you clone a request or response body, you're calling tee() - which splits a single stream into two branches that both need to be consumed. If one consumer reads faster than the other, data buffers unbounded in memory waiting for the slow branch. If you don't properly consume both branches, the underlying connection leaks. The coordination required between two readers sharing one source makes it easy to accidentally break the original request or exhaust connection pools. It's a simple API call with complex underlying mechanics that are difficult to get right." - Matteo Collina, Ph.D. - Platformatic Co-Founder & CTO, Node.js Technical Steering Committee Chair #### Falling headlong off the tee() memory cliff [tee()`](https://developer.mozilla.org/en-US/docs/Web/API/ReadableStream/tee) splits a stream into two branches. It seems straightforward, but the implementation requires buffering: if one branch is read faster than